This article is part 5 of the Blockchain train journal, start reading here: Catching the Blockchain Train.
The IPFS White Paper: IPFS Design
The IPFS stack is visualized as follows:

or with more detail:
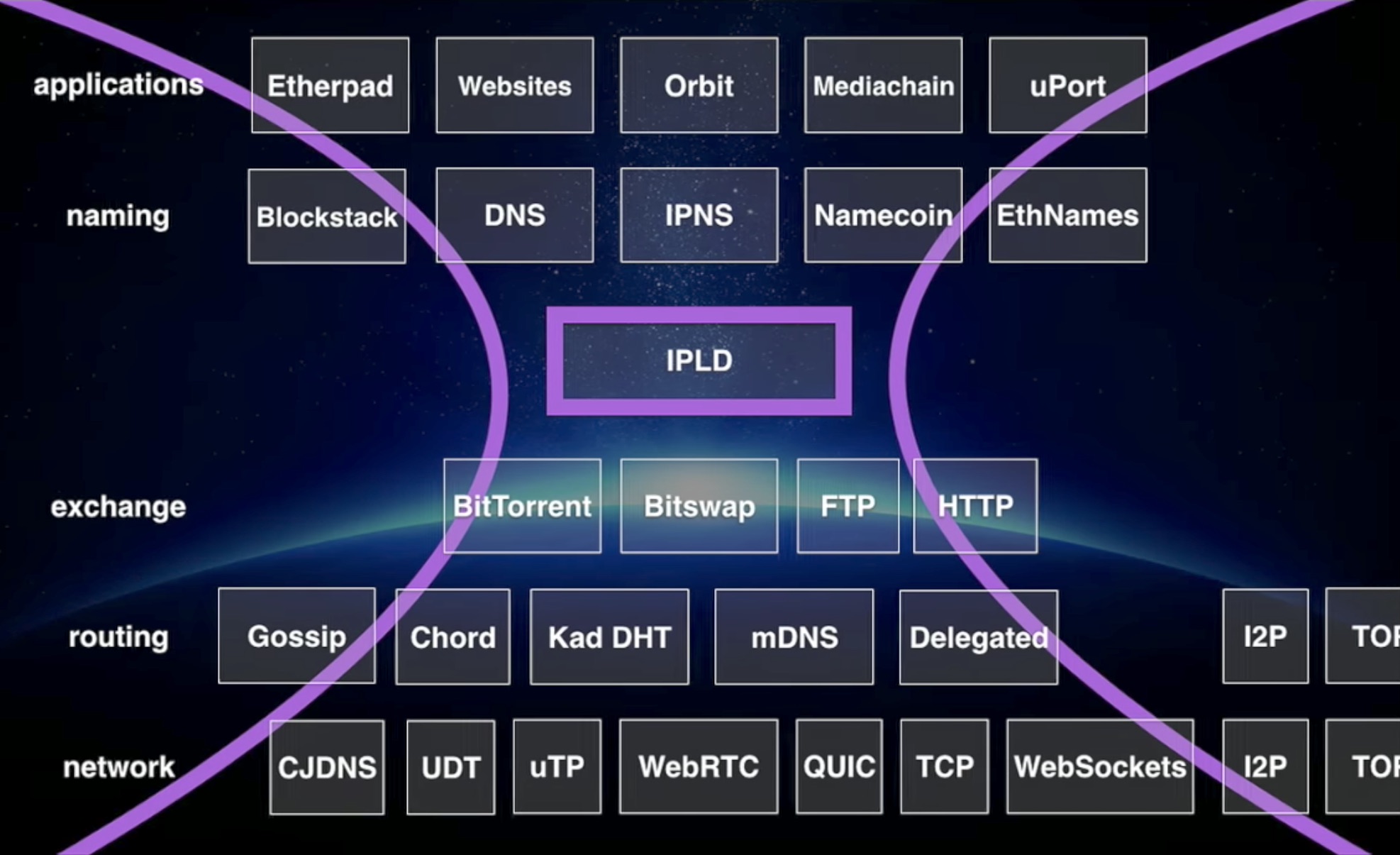
I borrowed both images from presentations by Juan Benet (the BDFL of IPFS).
The IPFS design in the white paper goes more or less through these layers, bottom-up:
The IPFS Protocol is divided into a stack of sub-protocols responsible for different functionality:
- Identities - manage node identity generation and verification.
- Network - manages connections to other peers, uses various underlying network protocols. Configurable.
- Routing - maintains information to locate specific peers and objects. Responds to both local and remote queries. Defaults to a DHT, but is swappable.
- Exchange - a novel block exchange protocol (BitSwap) that governs efficient block distribution. Modelled as a market, weakly incentivizes data replication. Trade Strategies swappable.
- Objects - a Merkle DAG of content-addressed immutable objects with links. Used to represent arbitrary data structures, e.g. file hierarchies and communication systems.
- Files - versioned file system hierarchy inspired by Git.
- Naming - A self-certifying mutable name system.
Here's my alternative naming of these sub-protocols:
- Identities: name those nodes
- Network: talk to other clients
- Routing: announce and find stuff
- Exchange: give and take
- Objects: organize the data
- Files: uh?
- Naming: adding mutability
Let's go through them and see if we can increase our understanding of IPFS a bit!
Identities: name those nodes
IPFS is a P2P network of clients; there is no central server. These clients are the nodes of the network and need a way to be identified by the other nodes. If you just number the nodes 1,2,3,... anyone can add a node with an existing ID and claim to be that node. To prevent that some cryptography is needed. IPFS does it like this:
- generate a PKI key pair (public + private key)
- hash the public key
- the resulting hash is the NodeId
All this is done during the init phase of a node: ipfs init > the resulting keys are stored in ~/.ipfs/config and returns the NodeId.
When two nodes start communicating the following happens:
- exchange public keys
- check if:
hash(other.PublicKey) == other.NodeId - if so, we have identified the other node and can e.g. request for data objects
- if not, we disconnect from the "fake" node
The actual hashing algorithm is not specified in the white paper, read the note about that here:
Rather than locking the system to a particular set of function choices, IPFS favors self-describing values. Hash digest values are stored in multihash format, which includes a short header specifying the hash function used, and the digest length in bytes.
Example:
\
\ \ This allows the system to (a) choose the best function for the use case (e.g. stronger security vs faster performance), and (b) evolve as function choices change. Self-describing values allow using different parameter choices compatibly.
These multihashes are part of a whole family of self-describing hashes, and it is brilliant, check it out: multiformats.
Network: talk to other clients
The summary is this: IPFS works on top of any network (see the image above).
Interesting here is the network addressing to connect to a peer. IPFS uses multiaddr formatting for that. You can see it in action when starting a node:
Swarm listening on /ip4/127.0.0.1/tcp/4001
Swarm listening on /ip4/172.17.0.1/tcp/4001
Swarm listening on /ip4/185.24.123.123/tcp/4001
Swarm listening on /ip6/2a02:1234:9:0:21a:4aff:fed4:da32/tcp/4001
Swarm listening on /ip6/::1/tcp/4001
API server listening on /ip4/127.0.0.1/tcp/5001
Gateway (read-only) server listening on /ip4/0.0.0.0/tcp/8080
Routing: announce and find stuff
The routing layer is based on a DHT, as discussed in the previous episode, and its purpose is to:
- announce that this node has some data (a
blockas discussed in the next chapter), or - find which nodes have some specific data (by referring to the multihash of a block), and
- if the data is small enough (=< 1KB) the DHT stores the data as its value.
The command line interface and API don't expose the complete routing interface as specified in the white paper. What does work:
# tell the DHT we have this specific content:
$ ipfs dht provide QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG
# ask for peers who have the content:
$ ipfs dht findprovs QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG
QmYebHWdWStasXWZQiXuFacckKC33HTbicXPkdSi5Yfpz6
QmczCvhy6unZEVC5ukR3BC3BPxYie4jBeRApTUKq97ZnEo
QmPM3WzZ3q1SR3pzXuGPHD7e6z3eWEWCnAvrNw7Wegyc8o
QmPKSqtkDmYsSxQbqNkZG1AmVnZSFyv5WF7fFE2YebNBFG
QmPMJ3HLLLBtW53R2YixhVHmVb3pkR2bHni3qbqq23vBSv
QmPNHJJphV1TB6Z99L6r9Y7bKaCBUQ67X17hicnEmsgWDJ
QmPNhiqGg81o2Perk2i7VNvvVuuLLUMKDxMNwVauP8r5Yv
QmPQJRgP3Vxi52Ho7HfnYdiCRJTRM1TXwgEnyjcwcLuKfb
QmNNxr1ZoyPbwNe2CvYz1CVyvSNWsE8WNwDWQ9t9BDjnj5
QmNT744VjtRFpDYB25EVLx7ha1zAVDKsd3qFjxfQLjPEXq
QmNWwGRWTYeut6qvKDhJBuEJZnbqMPMfuF81MPvHvPBX89
QmNZM5NmzZNPkvH2kPXDYNAB1cAeBNfxLyM9B1crgt3VeJ
QmNZRDzSJybdf4rmt972SH4U9TF6sEK8q2NSEJpEt7SkTp
QmNZdBUV9QXytVcPjcYM8i9AG22G2qwjZmh4ZwpJs9KvXi
QmNbSJ9okrwMphfjudiXVeE7QWkJiEe4JHHiKT8L4Pv7z5
QmNdqMkVqLTsJWj7Ja3oKwLNWcAYUkRjSZPg22B7rvKFMr
QmNfyHTzAetJGBFTRkXXHe5om13Qj4LLjd9SDwJ87T6vCK
QmNmrRTP5sJMUkobujpVXzzjpLACBTzf9weND6prUjdstW
QmNkGG9EZrq699KnjbENARLUg3HwRBC7nkojnmYY8joBXL
QmP6CHbxjvu5dxdJLGNmDZATdu3TizkRZ6cD9TUQsn4oxY
# Get all multiaddr's for a peer
$ ipfs dht findpeer QmYebHWdWStasXWZQiXuFacckKC33HTbicXPkdSi5Yfpz6
/ip4/192.168.1.14/tcp/4001
/ip6/::1/tcp/4001
/ip4/127.0.0.1/tcp/4001
/ip4/1.2.3.4/tcp/37665
ipfs put and ipfs get only work for ipns records in the API. Maybe storing small data on the DHT itself was not implemented (yet)?
Exchange: give and take
Data is broken up into blocks, and the exchange layer is responsible for distributing these blocks. It looks like BitTorrent, but it's different, so the protocol warrants its own name: BitSwap.
The main difference is that wherein BitTorrent blocks are traded with peers looking for blocks of the same file (torrent swarm), in BitSwap blocks are traded cross-file. So one big swarm for all IPFS data.
BitSwap is modeled as a marketplace that incentivizes data replication. The way this is implemented is called the BitSwap Strategy, and the white paper describes a feasible strategy and also states that the strategy can be replaced by another strategy. One such a bartering system can be based on a virtual currency, which is where FileCoin comes in.
Of course, each node can decide on its own strategy, so the generally used strategy must be resilient against abuse. When most nodes are set up to have some fair way of bartering it will work something like this:
- when peers connect, they exchange which blocks they have (
have_list) and which blocks they are looking for (want_list) - to decide if a node will actually share data, it will apply its
BitSwap Strategy - this strategy is based on previous data exchanges between these two peers
- when peers exchange blocks they keep track of the amount of data they share (builds credit) and the amount of data they receive (builds debt)
- this accounting between two peers is kept track of in the
BitSwap Ledger - if a peer has credit (shared more than received), our node will send the requested block
- if a peer has debt, our node will share or not share, depending on a deterministic function where the chance of sharing becomes smaller when the debt is bigger
- a data exchange always starts with the exchange of the ledger, if it is not identical our node disconnects
So this is set up kind of cool I think: game theory in action! The white paper further describes some edge cases like what to do if I have no blocks to barter with? The answer is simply to collect blocks that your peers are looking for, so you have something to trade.
Now let's have a look how we can poke around in the innards of the BitSwap protocol.
The command-line interface has a section blocks and a section bitswap; those sound relevant :)
To see bitswap in action, I'm going to request a large file Qmdsrpg2oXZTWGjat98VgpFQb5u1Vdw5Gun2rgQ2Xhxa2t which is a video (download it to see what video!):
# ask for the file
$ ipfs get Qmdsrpg2oXZTWGjat98VgpFQb5u1Vdw5Gun2rgQ2Xhxa2t
# in a seperate terminal, after requesting the file, I inspect the "bitswap wantlist"
$ ipfs bitswap wantlist
QmYEqofNsPNQEa7yNx93KgDycmrzbFkr5oc3NMKXMxx5ff
QmUmDEBm9a8MYyqRdb3YQnoqPmqAo4cEWdKQErirFJdSWD
QmY5VJPbsRZzFCTMrFBx2qtZiyyeLhsjBysyfC1fx2gE9S
QmdbzYgyhqUNCNL8xU2HTSKwao1ck2Gmi5U1ygjQuJd92b
QmbZDe5Dcv9mJr8fiqp5aJL2cbyu64tgzwCS2Vy4P3krCL
QmRjzMzVeYRE5b6tDF3sTXMV1sTffno92uL3WwuFavBrWQ
QmPavzEJQw8atvErXQis6C6GF7DRFbb95doAaFkHe9M38u
QmY9fs1Pkr3nV7RkbGdfGh3q8HuKtMMCCUp22AAbwPYnrS
QmUtxZkuJuyydd124Z2cfx6jXMAMpcXZRF96QMAsXc2y6c
QmbYDTJkmLqMm6ojdL6pLP7C8mMVfVPnUxn3yp8HzXDcXf
QmbW9MZ7cwn8svpixosAuC7GQmUXDTZRuxJ8dJp6HyJzCS
QmdCLGWsYQFhi9y3BmkhUreX2S799iWGyJqvnbK9dzB55c
Qmc7EvnBPf2mPCUCfvjcsaQGLEakBbUN9iycnyrLF3b2or
Qmd1mNnDQPf1BAjFqDHjiLe4g4ZFPAheQCniYkbQPosjDE
QmPip8XzQhJFd487WWw7D8aBuGLwXtohciPtUDSnxpvMFR
QmZn5NAPEDtptMb3ybaMEdcVaoxWHs7rKQ4H5UBcyHiqTZ
.
.
.
# find a node where we have debt
$ ipfs dht findprovs Qmdsrpg2oXZTWGjat98VgpFQb5u1Vdw5Gun2rgQ2Xhxa2t
QmSoLMeWqB7YGVLJN3pNLQpmmEk35v6wYtsMGLzSr5QBU3
QmSoLnSGccFuZQJzRadHn95W2CrSFmZuTdDWP8HXaHca9z
QmUh2KnjAvgEbJFSd5JZws4CNvt6LbC4C1sRpBgCbZQiqD
Qmc9pBLfKSwWboKHMvmKx1P7Z738CojuUXkPA1dsPrvSw2
QmZFhGyS2W833nKKkbqZAU2uSvBbWUytDJkKBHimwRmhd6
QmZMxNdpMkewiVZLMRxaNxUeZpDUb34pWjZ1kZvsd16Zic
Qmbut9Ywz9YEDrz8ySBSgWyJk41Uvm2QJPhwDJzJyGFsD6
# try one to see if we have downloaded from that node
$ ipfs bitswap ledger QmSoLMeWqB7YGVLJN3pNLQpmmEk35v6wYtsMGLzSr5QBU3
Ledger for <peer.ID SoLMeW>
Debt ratio: 0.000000
Exchanges: 11
Bytes sent: 0
Bytes received: 2883738
Thank you QmSoLMeWqB7YGVLJN3pNLQpmmEk35v6wYtsMGLzSr5QBU3; what a generous peer you are!
Now, have a look at the block commands:
# Let's pick a block from the wantlist above
$ ipfs block stat QmYEqofNsPNQEa7yNx93KgDycmrzbFkr5oc3NMKXMxx5ff
Key: QmYEqofNsPNQEa7yNx93KgDycmrzbFkr5oc3NMKXMxx5ff
Size: 262158
$ ipfs block get QmYEqofNsPNQEa7yNx93KgDycmrzbFkr5oc3NMKXMxx5ff > slice_of_a_movie
# results in a binary file of 262 KB
We'll have another look at how blocks fit in in the next chapter.
The three layers of the stack we described so far (network, routing, exchange) are implemented in libp2p.
Let's climb up the stack to the core of IPFS...
Objects: organize the data
Now it gets fascinating. You could summarize IPFS as: Distributed, authenticated, hash-linked data structures. These hash-linked data structures are where the Merkle DAG comes in (remember our previous episode?).
To create any data structure, IPFS offers a flexible and powerful solution:
- organize the data in a graph, where we call the nodes of the graph
objects - these objects can contain data (any sort of data, transparent to IPFS) and/or links to other objects
- these links -
Merkle Links- are simply the cryptographic hash of the target object
This way of organizing data has a couple of useful properties (quoting from the white paper):
- Content Addressing: all content is uniquely identified by its multihash checksum, including links.
- Tamper resistance: all content is verified with its checksum. If data is tampered with or corrupted, IPFS detects it.
- Deduplication: all objects that hold the exact same content are equal, and only stored once. This is particularly useful with index objects, such as git trees and commits, or common portions of data.
To get a feel for IPFS objects, check out this objects visualization example.
Another nifty feature is the use of unix-style paths, where a Merkle DAG has the structure:
/ipfs/<hash-of-object>/<named-path-to-object
We'll see an example below.
This is really all there is to it. Lets see it in action by replaying some examples from the quick-start:
$ mkdir foo
$ mkdir foo/bar
$ echo "baz" > foo/baz
$ echo "baz" > foo/bar/baz
$ tree foo/
foo/
├── bar
│ └── baz
└── baz
$ ipfs add -r foo
added QmWLdkp93sNxGRjnFHPaYg8tCQ35NBY3XPn6KiETd3Z4WR foo/bar/baz
added QmWLdkp93sNxGRjnFHPaYg8tCQ35NBY3XPn6KiETd3Z4WR foo/baz
added QmeBpzHngbHes9hoPjfDCmpNHGztkmZFRX4Yp9ftKcXZDN foo/bar
added QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm foo
# the last hash is the root-node, we can access objects through their path starting at the root, like:
$ ipfs cat /ipfs/QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm/bar/baz
baz
# To inspect an object identified by a hash, we do
$ ipfs object get /ipfs/QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm
{
"Links":[
{
"Name":"bar",
"Hash":"QmeBpzHngbHes9hoPjfDCmpNHGztkmZFRX4Yp9ftKcXZDN",
"Size":61
},
{
"Name":"baz",
"Hash":"QmWLdkp93sNxGRjnFHPaYg8tCQ35NBY3XPn6KiETd3Z4WR",
"Size":12
}
],
"Data":"\u0008\u0001"
}
# The above object has no data (except the mysterious \u0008\u0001) and two links
# If you're just interested in the links, use "refs":
$ ipfs refs QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm
QmeBpzHngbHes9hoPjfDCmpNHGztkmZFRX4Yp9ftKcXZDN
QmWLdkp93sNxGRjnFHPaYg8tCQ35NBY3XPn6KiETd3Z4WR
# Now a leaf object without links
$ ipfs object get /ipfs/QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm/bar/baz
{
"Links":[
],
"Data":"\u0008\u0002\u0012\u0004baz\n\u0018\u0004"
}
# The string 'baz' is somewhere in there :)
The Unicode characters that show up in the data field are the result of serialization of the data. IPFS uses protobuf for that I think. Correct me if I'm wrong :)
At the time I'm writing this there is an experimental alternative for the ipfs object commands: ipfs dag:
$ ipfs dag get QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm
{
"data":"CAE=",
"links":[
{
"Cid":{
"/":"QmeBpzHngbHes9hoPjfDCmpNHGztkmZFRX4Yp9ftKcXZDN"
},
"Name":"bar",
"Size":61
},
{
"Cid":{
"/":"QmWLdkp93sNxGRjnFHPaYg8tCQ35NBY3XPn6KiETd3Z4WR"
},
"Name":"baz",
"Size":12
}
]
}
$ ipfs dag get /ipfs/QmdcYvbv8FSBfbq1VVSfbjLokVaBYRLKHShpnXu3crd3Gm/bar/baz
{
"data":"CAISBGJhegoYBA==",
"links":[
]
}
We see a couple of differences there, but let's not get into that. Both outputs follow the IPFS object format from the white paper. One interesting bit is the "Cid" that shows up; this refers to the newer Content IDentifier.
Another feature that is mentioned is the possibility to pin objects, which results in storage of these objects in the file system of the local node. The current go implementation of ipfs stores it in a leveldb database under the ~/.ipfs/datastore directory. We have seen pinning in action in a previous post.
The last part of this chapter mentions the availability of object level encryption. This is not implemented yet: status wip (Work in Progress; I had to look it up as well). The project page is here: ipfs keystore proposal.
The ipfs dag command hints to something new...
Intermission: IPLD
If you studied the images at the start of this post carefully, you are probably wondering, what is IPLD and how does it fit in? According to the white paper, it doesn't fit in, as it isn't mentioned at all!
My guess is that IPLD is not mentioned because it was introduced later, but it more or less maps to the Objects chapter in the paper. IPLD is broader, more general, than what the white paper specifies. Hey Juan, update the white paper will ya! :-)
If you don't want to wait for the updated white paper, have a look here: the IPLD website (Inter Planetary Linked Data), the IPLD specs and the IPLD implementations.
And this video is an excellent introduction: Juan Benet: Enter the Merkle Forest.
But if you don't feel like reading/watching more: IPLD is more or less the same as what is described in the "Objects" and "Files" chapters here.
Moving on to the next chapter in the white paper...
Files: uh?
On top of the Merkle DAG objects IPFS defines a Git-like file system with versioning, with the following elements:
blob: there is just data in blobs and it represents the concept of a file in IPFS. No links in blobslist: lists are also a representation of an IPFS file, but consisting of multiple blobs and/or liststree: a collection of blobs, lists and/or trees: acts as a directorycommit: a snapshot of the history in a tree (just like a git commit).
Now I hear you thinking: aren't these blobs, lists, and trees the same things as what we saw in the Mergle DAG? We had objects there with data, with or without links, and nice Unix-like file paths.
I heard you thinking that because I thought the same thing when I arrived at this chapter. After searching around a bit I started to get the feeling that this layer was discarded and IPLD stops at the "objects" layer, and everything on top of that is open to whatever implementation. If an expert is reading this and thinks I have it all wrong: please let me know, and I'll correct it with the new insight.
Now, what about the commit file type? The title of the white paper is "IPFS - Content Addressed, Versioned, P2P File System", but the versioning hasn't been implemented yet it seems.
There is some brainstorming going on about versioning here and here.
That leaves one more layer to go...
Naming: adding mutability
Since links in IPFS are content addressable (a cryptographic hash over the content represents the block or object of content), data is immutable by definition. It can only be replaced by another version of the content, and it, therefore, gets a new "address".
The solution is to create "labels" or "pointers" (just like git branches and tags) to immutable content. These labels can be used to represent the latest version of an object (or graph of objects).
In IPFS this pointer can be created using the Self-Certified Filesystems I described in the previous post. It is named IPNS and works like this:
- The root address of a node is
/ipns/<NodeId> - The content it points to can be changed by publishing an IPFS object to this address
- By publishing, the owner of the node (the person who knows the secret key that was generated with
ipfs init) cryptographically signs this "pointer". - This enables other users to verify the authenticity of the object published by the owner.
- Just like IPFS paths, IPNS paths also start with a hash, followed by a Unix-like path.
- IPNS records are announced and resolved via the DHT.
I already showed the actual execution of the ipfs publish command in the post Getting to know IPFS.
This chapter in the white paper also describes some methods to make addresses more human-friendly, but I'll leave that in store for the next episode which will be hands-on again. We gotta get rid of these hashes in the addresses and make it all work nicely in our good old browsers: Ten terrible attempts to make IPFS human-friendly
Let me know what you think of this post by tweeting to me @pors!